【データに潜む猫】カテゴリ特徴量のエンコード方法まとめ
カテゴリ特徴量(categorical features)を機械学習モデルで扱うためのエンコード方法についてまとめる.

- 全人類が読むべき参考文献
- カテゴリ特徴量の種類
- データセット:Categorical Feature Encoding Challenge
- 基本のエンコード
- 応用っぽいエンコード
- まとめ・今後の課題(To Do)
全人類が読むべき参考文献
kaggleのカテゴリ特徴量に関するチュートリアル. www.kaggle.com
カテゴリ特徴量に関するkaggleコンペティション.このコンペで用いられているデータセットを使う. www.kaggle.com www.kaggle.com
上記コンペのNotebook.全人類が読むべき. www.kaggle.com
特徴量エンジニアリング全般に関する教科書.カテゴリ特徴量以外の扱い(テキストのBoW表現やTF-IDFなど)についても充実している. www.oreilly.co.jp
カテゴリ特徴量の種類
そもそもカテゴリ特徴量はその名の通りカテゴリやラベルを表す特徴量であり,基本的には数値でない特徴量のこと. 例えば「年齢」とか「体重」なんかは数値なのでそのまま機械学習モデルに入力できるけど,「性別」とか「職業」なんかは数値じゃないのでそのまま機械学習モデルに入力できない. そこで,そんなカテゴリ特徴量を機械学習モデルに入力できるように数値に変換(エンコード)することを考えるのだけど,そのカテゴリ特徴量の意味や性質をちゃんと考慮して変換しないと予測に必要な情報が欠落してしまうので,適切な変換方法を選択する必要がある.
以下は,代表的なカテゴリ特徴量の種類.日本語訳は正しくないかもしれない.
二値特徴量(binary features)
その名の通り2種類の値のみをとる特徴量. 「Yes・No」,「◯◯以上・◯◯未満」,「きのこ派・たけのこ派」など. 「性別(男・女)」が代表的な例だと思ってたけど,近年だと怒られが発生しそうですね...
名目特徴量(nominal features)
ある限られた種類の値(カテゴリ)をとる特徴量. 「色(赤・青・黄)」,「ペット(猫・犬・インコ・その他)」などだろうか. このとき,各カテゴリの間には順序関係がないことに注意する. 例えば,猫と犬の間に「猫 < 犬」のような順序関係は(個々人の宗教観にも依存すると思うが)一般的に存在しない. 次の順序特徴量(ordinal features)と比較して非順序特徴量(nonordinal features)と呼ぶこともあるらしい.
順序特徴量(ordinal features)
各カテゴリの間に順序関係がある特徴量. 例えば「朝食(毎日摂る・ほぼ毎日摂る・たまに摂る・摂らない)」という特徴量には,「毎日摂る > ほぼ毎日摂る > たまに摂る > 摂らない」というような順序関係があると考えることができる.
循環特徴量(cyclic features)
各カテゴリの間に循環する性質がある特徴量. わかりやすい例は「曜日(月・火・...・日)」. 各曜日の隣接関係を考えた時に,「月→火→...→日→月→...」と循環していることを考慮してエンコードする必要がある.
データセット:Categorical Feature Encoding Challenge
カテゴリ特徴量に関するkaggleコンペ「Categorical Feature Encoding Challenge」のデータセットを使って いくつかのエンコード方法を試してみる.予測タスクは二値分類問題.
データセットに含まれる特徴量や予測値(ターゲット)の意味に関する説明はない.
データセットを pandas の DataFrame で読み込んで,とりあえずどんな特徴量が含まれているか確認する.
import pandas as pd train = pd.read_csv('data/train.csv') X = train.drop(['id', 'target'], axis=1) y = train['target'] print(X.columns)
Index(['bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4', 'nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4', 'nom_5', 'nom_6', 'nom_7', 'nom_8', 'nom_9', 'ord_0', 'ord_1', 'ord_2', 'ord_3', 'ord_4', 'ord_5', 'day', 'month'], dtype='object')
各特徴量は匿名化されていて,カテゴリ特徴量の種類に応じて機械的に名前がつけられている. (名前から推測できるけど)中身の値を見てみると,
'bin_0', 'bin_1', 'bin_2', 'bin_3', 'bin_4'が二値特徴量,'nom_0', 'nom_1', 'nom_2', 'nom_3', 'nom_4', 'nom_5', 'nom_6', 'nom_7', 'nom_8', 'nom_9'が名目特徴量,'ord_0', 'ord_1', 'ord_2', 'ord_3', 'ord_4', 'ord_5'が順序特徴量,'day', 'month'が循環特徴量,
という感じになっている.わかりやすいですね.それぞれ具体的なカテゴリを見てみると,
for col in ['bin_4', 'nom_0', 'ord_1', 'month']: print(col, ':', X[col].unique())
bin_4 : ['Y' 'N'] nom_0 : ['Green' 'Blue' 'Red'] ord_1 : ['Grandmaster' 'Expert' 'Novice' 'Contributor' 'Master'] month : [ 2 8 1 4 10 3 7 9 12 11 5 6]
という感じ.このとき, 「Novice < Contributor < Expert < Master < Grandmaster」 という順序関係*1があることや, 「1月→2月→...→12月→1月→...」といったように循環する性質があることに注意する.
基本のエンコード
代表的なエンコード方法として, ラベルエンコーディングとOne-Hotエンコーディングを 取り上げる*2.
ラベルエンコーディング
各カテゴリにそれぞれ異なる整数値をラベルとして割り当てる. 以下はカテゴリ特徴量「Breakfast(Every day・Most days・Rarely・Never)」に対するラベルエンコーディングの一例. それぞれのカテゴリに「Never : 0」,「Rarely : 1」,「Most days : 2」,「Every day : 3」,といったように整数値を割り当てている. カテゴリ間の順序関係(Every day > Most days > Rarely > Never)と整数値の順序関係が一致していていい感じに見える.

ラベルエンコーディングは sklearn.prepocessing の LabelEndocer として実装されている.
LabelEndocer を使って順序特徴量 'ord_1' をラベルエンコーディングしてみると,
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() X['ord_1_enc'] = le.fit_transform(X['ord_1']) print(X[['ord_1','ord_1_enc']][:10])
ord_1 ord_1_enc 0 Grandmaster 2 1 Grandmaster 2 2 Expert 1 3 Grandmaster 2 4 Grandmaster 2 5 Novice 4 6 Grandmaster 2 7 Novice 4 8 Novice 4 9 Expert 1
という感じで,「Novice : 4」,「Contributor : 0」,「Expert : 1」,「Master : 3」,「Grandmaster : 2」, というように自動的に整数値を割り当てて変換してくれる. どうやらカテゴリ名の辞書順で整数値を割り当てているようだ.
しかし,実際は「Novice < Contributor < Expert < Master < Grandmaster」 という順序関係を表現したいので,
「Novice : 0」,「Contributor : 1」,「Expert : 2」,「Master : 3」,「Grandmaster : 4」となってほしい.
ちょっと強引だが,このような順序関係があらかじめわかっていれば,pandas.DataFrame の map を使って実現できる.
map_dict = {'Novice' : 0, 'Contributor' : 1, 'Expert' : 2, 'Master' : 3, 'Grandmaster' : 4}
X['ord_1_enc'] = X['ord_1'].map(map_dict)
print(X[['ord_1','ord_1_enc']][:10])
ord_1 ord_1_enc 0 Grandmaster 4 1 Grandmaster 4 2 Expert 2 3 Grandmaster 4 4 Grandmaster 4 5 Novice 0 6 Grandmaster 4 7 Novice 0 8 Novice 0 9 Expert 2
めでたしめでたし.
ところで,同じようにLabelEndocer を使って名目特徴量 'nom_0' をラベルエンコーディングしてみると,
le = LabelEncoder() X['nom_0_enc'] = le.fit_transform(X['nom_0']) print(X[['nom_0','nom_0_enc']][:10])
nom_0 nom_0_enc 0 Green 1 1 Green 1 2 Blue 0 3 Red 2 4 Red 2 5 Blue 0 6 Green 1 7 Red 2 8 Blue 0 9 Red 2
となり,「Green : 1」,「Blue : 0」,「Red : 2」という感じで各カテゴリに整数値を割り当ててくれる. 一見するといい感じだが,「Blue < Green < Red」という順序関係ができてしまっているので,この特徴量に対しては適切でない. これを解決する方法の一つとして,次に紹介するOne-Hotエンコーディングがある.
One-Hotエンコーディング
カテゴリ毎にダミー特徴量を新しく作り,そのカテゴリに該当するなら 1 を,そうでないなら 0 とする. 以下はカテゴリ特徴量「Color(Red・Yellow・Green)」に対するOne-Hotエンコーディングの一例. Red,Yellow,Greenをそれぞれ表すダミー特徴量を新しく作り,対応する色の特徴量の値は 1 に,それ以外の値は 0 にしている.

One-Hotエンコーディングは sklearn.prepocessing の OneHotEncoder として実装されているが
pandas.get_dummies の方が簡単な気がするのでそちらを使ってみる.
get_dummies を使って名目特徴量 'nom_0' をOne-Hotエンコーディングしてみる.
prefix_sep=':' と指定して pandas.DataFrame を渡すと,「特徴量名:カテゴリ名」という形でダミー特徴量を作ってくれる.
dum = pd.get_dummies(X[['nom_0']], prefix_sep=':') X = pd.concat([X, dum], axis=1) print(X[['nom_0', 'nom_0:Blue', 'nom_0:Green', 'nom_0:Red']][:10])
nom_0 nom_0:Blue nom_0:Green nom_0:Red 0 Green 0 1 0 1 Green 0 1 0 2 Blue 1 0 0 3 Red 0 0 1 4 Red 0 0 1 5 Blue 1 0 0 6 Green 0 1 0 7 Red 0 0 1 8 Blue 1 0 0
'nom_0:Blue','nom_0:Green','nom_0:Red'というダミー特徴量を新しく作り,
対応する色のダミー特徴量だけ 1 が立つようにしてくれる.
機械学習モデルとして決定木などを使うならこのままでも問題ないが,
ロジスティック回帰などの線形なモデルを使う場合は多重共線性(マルチコ)が問題になる.
線形モデルを使う場合は drop_first = True とすることで最初のカテゴリのダミー変数を除外できる.
dum = pd.get_dummies(X[['nom_0']], prefix_sep=':', drop_first=True) print(pd.concat([X['nom_0'], dum], axis=1)[:10])
nom_0 nom_0:Green nom_0:Red 0 Green 1 0 1 Green 1 0 2 Blue 0 0 3 Red 0 1 4 Red 0 1 5 Blue 0 0 6 Green 1 0 7 Red 0 1 8 Blue 0 0 9 Red 0 1
応用っぽいエンコード
ここまでで取り上げたエンコード方法を使えば,少なくともカテゴリ特徴量を機械学習モデルの入力として扱うことができるようになる. しかし,機械学習モデルの予測精度を向上させるためには,特徴量の持つ情報をより多く表現できるようなエンコードを行うことが必要. 機械学習モデルだけでは拾い切れない情報を,特徴量のエンコードに如何にして反映させるか, というのがデータサイエンティストとしての腕の見せ所,という風潮がある(ような気がする).
統計量を用いたエンコーディング
ラベルエンコーディングのラベルとして,単なる整数値を割り当てるのではなく,各カテゴリの何らかの統計量を用いる. これによって機械学習モデルが拾えない各カテゴリの統計的な性質を表せるだけでなく,カテゴリ間の類似度のようなものも表現できる.
とりあえず簡単なところで,カテゴリ特徴量 nom_0,ord_1,month に対して,
データセット X における各カテゴリの出現回数をデータ数で割った値(出現確率)をラベルとして割り当ててみる.
各カテゴリの出現回数は value_counts() を使うと簡単に数えることができる.
cols = ['nom_0', 'ord_1', 'month'] for col in cols: X[col+'_freq'] = X[col].map(dict(X[col].value_counts())) / X.shape[0] print(X[['nom_0', 'nom_0_freq', 'ord_1', 'ord_1_freq', 'month', 'month_freq']][:10])
nom_0 nom_0_freq ord_1 ord_1_freq month month_freq 0 Green 0.424470 Grandmaster 0.258093 2 0.151017 1 Green 0.424470 Grandmaster 0.258093 8 0.062433 2 Blue 0.320553 Expert 0.083550 2 0.151017 3 Red 0.254977 Grandmaster 0.258093 1 0.136160 4 Red 0.254977 Grandmaster 0.258093 8 0.062433 5 Blue 0.320553 Novice 0.421943 2 0.151017 6 Green 0.424470 Grandmaster 0.258093 4 0.083067 7 Red 0.254977 Novice 0.421943 2 0.151017 8 Blue 0.320553 Novice 0.421943 4 0.083067 9 Red 0.254977 Expert 0.083550 2 0.151017
こうやって見てみると,†最強†の称号である「Grandmaster」がデータセット全体の25%もいることが判明する. どういうデータセットなんだこれは......
循環特徴量のエンコード
循環する性質のある特徴量(cyclic features)に対しては,三角関数(sinやcos)を使ったエンコードがよく使われるらしい. 例えば,カテゴリ特徴量「月(Jan・Feb・...・Dec)」はラベルエンコーディングにより 「Jan : 1」,「Feb : 2」,...,「Dec : 12」,というように変換してあげると直感的にもわかりやすい. しかし,実際は下図に示されるような循環する性質(Jan → Feb → ... → Dec → Jan → ...)があるので, これを考慮するために三角関数を用いるんだとか.
三角関数を使って循環特徴量 'month' をエンコードしてみる.
データセットのままで既にラベルエンコーディングされているので,直接三角関数に適用できる.
具体的には,次に示すような式でエンコードを行う:
三角関数は numpy に実装されているのでそれを使う.
X['month_sin'] = np.sin((2 * np.pi * X['month'])/(max(X['month']))) X['month_cos'] = np.cos((2 * np.pi * X['month'])/(max(X['month']))) print(X[['month','month_sin','month_cos']][:10])
month month_sin month_cos 0 2 0.866025 0.500000 1 8 -0.866025 -0.500000 2 2 0.866025 0.500000 3 1 0.500000 0.866025 4 8 -0.866025 -0.500000 5 2 0.866025 0.500000 6 4 0.866025 -0.500000 7 2 0.866025 0.500000 8 4 0.866025 -0.500000 9 2 0.866025 0.500000
いちおうOne-Hotエンコーディングした特徴量も併用するとよいかもしれない.
ターゲットエンコーディング
予測値(ターゲット)に関する何らかの統計量を使って各カテゴリをラベルエンコーディングする. 予測精度を向上させ得るkaggler御用達テクニックの一つだが, リーク(本来参照できないターゲット情報を使うことによる過学習)が起きやすいため扱いには注意が必要. 以下の記事が詳しい.全人類が読むべき.
各カテゴリにおけるターゲットの平均値をラベルとして割り当てる Target Mean Encoding をやってみる.
今回は二値分類()なので,ターゲットの平均値は
をとる確率と見なせなくもない.
順序特徴量
'ord_1' についてターゲットの平均値を計算してみると,
cats = ['Novice', 'Contributor', 'Expert', 'Master', 'Grandmaster'] for cat in cats: print(cat, ':', y[X['ord_1']==cat].mean())
Novice : 0.24205462028866437 Contributor : 0.2785332742413286 Expert : 0.31717534410532616 Master : 0.3550778882828931 Grandmaster : 0.40388489951955364
という感じでカテゴリの順序関係とターゲットの平均値( をとる確率)の大小関係が一致した.なんか重要な特徴量っぽい.
このままターゲットの平均値を各カテゴリのラベルとして使えそうに思えるが,この方法はリークが起きているのであまり好ましくない. すなわち,この方法ではデータセット全体でターゲットの統計量を集計しているので, 各データをエンコードするために自身に紐づいている予測値の情報をも使っているということになる. しかし,本来それは参照できない,というか,してはいけない情報なので,リークが起きて過学習に繋がる可能性がある.
リークを防ぐために,K-Fold ターゲットエンコーディングをする. 考え方はもうK-Fold 交差検証(CV)と同じで,以下の操作をK-Fold CVと同様の要領で行う:
以下は具体例. カテゴリ「A」と「B」について,Fold-2〜Fold-5 のデータを使ってそれぞれターゲットの平均値を計算して, その値を Fold-1 のデータにおける各カテゴリのラベルとして用いる.これを各 Fold について繰り返す.
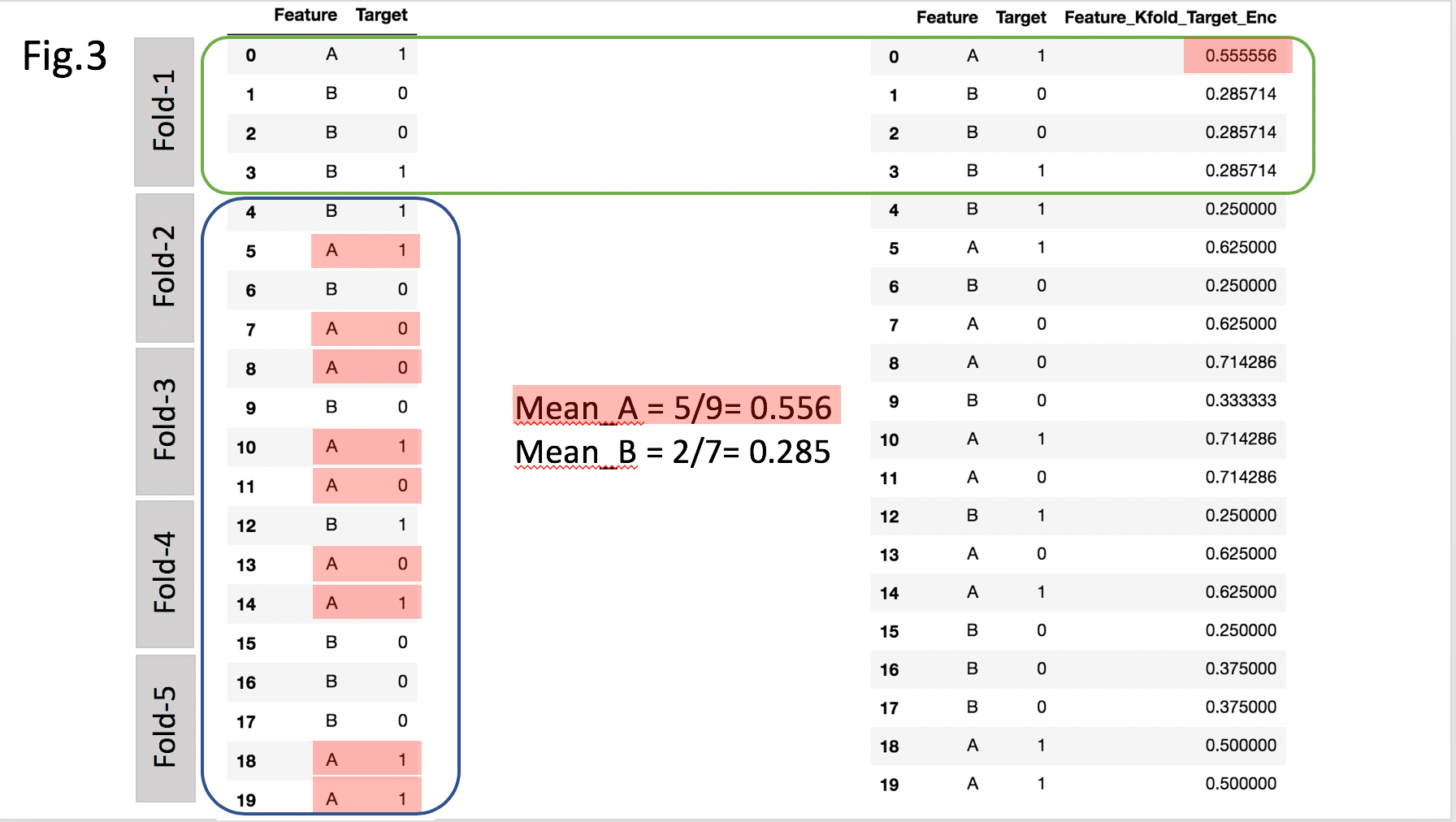
便利なライブラリは無さそうなので,sklearn.model_selection の KFold を使ってしこしこがんばる.
from sklearn.model_selection import KFold kf = KFold(n_splits=10) for tr, vl in kf.split(X): stats = [] for cat in cats: stats.append(y[tr][X.loc[tr, 'ord_1']==cat].mean()) map_dict = dict(zip(cats, stats)) X.loc[vl, 'ord_1_te'] = X.loc[vl, 'ord_1'].map(map_dict) print(X[['ord_1','ord_1_te']].head(10)) print(X[['ord_1','ord_1_te']].tail(10))
ord_1 ord_1_te
0 Grandmaster 0.404199
1 Grandmaster 0.404199
2 Expert 0.317650
3 Grandmaster 0.404199
4 Grandmaster 0.404199
5 Novice 0.241325
6 Grandmaster 0.404199
7 Novice 0.241325
8 Novice 0.241325
9 Expert 0.317650
ord_1 ord_1_te
299990 Master 0.355656
299991 Contributor 0.277845
299992 Master 0.355656
299993 Grandmaster 0.404512
299994 Novice 0.241775
299995 Contributor 0.277845
299996 Novice 0.241775
299997 Novice 0.241775
299998 Master 0.355656
299999 Contributor 0.277845
かなりわかりづらいが,よく見るとデータセットの先頭部分と末尾部分で割り当てられたラベルとしての値が微妙に異なっている.
例えば「Grandmaster」に割り当てられた値は,データセットの先頭では 0.404199 で,末尾では 0.404512 になっている.
まとめ・今後の課題(To Do)
エンコード方法による予測精度の違いについても検証すべきなんですけどね...
実際はデータセットやモデルに依存して使うべきエンコード方法も変わってくるので, そういうのを探る作業は本当に地道というか泥臭い印象があり, データサイエンスってカッコいい名前のわりに大変だよなぁというお気持ちになるのであった.